根据中国国家海洋局2012年9月16日公布坐标数据, 画了《钓鱼岛及其部分附属岛屿图》。
最近关于美国国债的新闻和议论充斥媒体。为给自己“扫盲”,读了以下文章:
-
John Steele Gordon, "A Short History of the National Debt," The Wall Street Journal, http://online.wsj.com/article/SB123491373049303821.html.
-
向松祚, "大历史视角的美国国债和美元霸权", http://www.caogen.com/blog/Infor_detail.aspx?ID=117&articleId=28690。
-
Wikipedia contributors, "United States public debt," Wikipedia, The Free Encyclopedia, http://en.wikipedia.org/w/index.php?title=Plagiarism&oldid=5139350. And the series of articles on United States budget and debt topics.
最大感慨——美国是从英国独立出来的,所以继承了很多英国的传统,包括中央银行、国债这样的17、18世纪起源于英国的金融概念,它们也很自然地成为美国立国政治家们熟悉和必然的思维方式和工具,而用于美国的独立和壮大。美国首任财政部长 Alexander Hamilton (美国纸币上出现的唯一不是总统的人,在 $10 上)高瞻远瞩地在立国初期就系统建立了一个长期的国家金融策略。美国国债其实就是美国给世界发的“白条”,把美国的未来繁荣和别的国家的财富捆绑起来。而美元作为国际交易结算媒介,是一个强有力地控制世界经济的手段,使全世界人民创造的价值源源不断地流入美国。
吕形叠字
品形叠字
| 品行字 | 读音 | 查询 zdic.net | ||
|---|---|---|---|---|
| 牛 |
犇
|
bēn | 犇 | |
| 贝 |
赑
|
bì | 赑 | |
| 犬 |
猋
|
biāo | 猋 | |
| 马 |
骉
|
biāo | 骉 | |
| 馬 |
驫
|
biāo | 驫 | |
| 雷 |
靐
|
bìng | 靐 | |
| 鹿 |
麤
|
cū | 麤 | |
| 直 |
矗
|
chù | 矗 | |
| 毛 |
毳
|
cuì | 毳 | |
| 飛 |
飝
|
fēi | 飝 | |
| 车 |
轟
|
hōng | 轟 | |
| 日 |
晶
|
jīng | 晶 | |
| 田 |
畾
|
lěi | 畾 | |
| 石 |
磊
|
lěi | 磊 | |
| 刀 |
刕
|
lí | 刕 | |
| 力 |
劦
|
lie | 劦 | |
| 水 |
淼
|
miǎo | 淼 | |
| 小 |
尛
|
mó | 尛 | |
| 目 |
瞐
|
mò | 瞐 | |
| 耳 |
聶
|
niè | 聶 | |
| 手 |
掱
|
pá | 掱 | |
| 口 |
品
|
pǐn | 品 | |
| 舌 |
舙
|
qì | 舙 | |
| 又 |
叒
|
ruò | 叒 | |
| 止 |
歮
|
sè | 歮 | |
| 木 |
森
|
sēn | 森 | |
| 羊 |
羴
|
shān | 羴 | |
| 心 |
惢
|
suǒ | 惢 | |
| 言 |
譶
|
tà | 譶 | |
| 龍 |
龘
|
tà、dá | 龘 | |
| 風 |
飍
|
xiū | 飍 | |
| 魚 |
鱻
|
xiān | 鱻 | |
| 白 |
皛
|
xiǎo | 皛 | |
| 金 |
鑫
|
xīn | 鑫 | |
| 香 |
馫
|
xīn | 馫 | |
| 泉 |
灥
|
xún | 灥 | |
| 火 |
焱
|
yàn | 焱 | |
| 土 |
垚
|
yáo | 垚 | |
| 原 |
厵
|
yuán | 厵 | |
| 隼 |
雥
|
zá | 雥 | |
| 吉 |
嚞
|
zhé | 嚞 | |
| 人 |
众
|
zhòng | 众 | |
| 士 |
壵
|
zhuàng | 壵 | |
| 子 |
孨
|
zhuǎn | 孨 | |
jí形叠字
口口
口口
(四个口字,上下各两个)
- jí: 1.1 众口也。 1.2 喧哗。
- léi: 2.1 同雷,古雷字。 2.2 一种有机化合物名,(porphine)。或称卟(bǔ)吩。
参考文献:《汉语大字典》
(under construction)
吅形叠字
吅
- xuān: 古同“喧”,大声呼叫。
- sòng: 古同“讼”,诉讼。
例:
囍
雦形叠字
Unicode 7 was released in June. I read the release news and was intrigued to review various concepts about Unicode and character encoding in general, since such is one of those technical issues that one encounter frequently, usually without appreciating or understanding its full technicality (due to its terseness and complexity), hence not sufficiently carefully taking care of it in general. But, if you're unlucky as every living man will be sometime, it bites back on you and you'll have to pay back the technical debt.
The first few articles I read some years ago on the topic besides the obvious Wikipedia articles, was Joel Spolsky's oft-referenced article 〈The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)〉 which humorously introduced the history, motivation, and basic ideas to the various concepts and practical information about character sets, Unicode and UTF-8. In my native tongue Chinese, RUAN Yifeng (阮一峰) has a reading note article about the topic which explains the basics clearly and succinctly. Xah Lee wrote a series of concise summaries about Unicode characters. (They are also particularly neatly formatted using HTML & CSS.) Some articles summarize interesting subsets of characters such as the arrow characters which I find quite handy as reference.
My short mnemonic on the topic, for now is just the following
few sentences: Unicode is a character set, which is intended to be
a unified set containing characters in all languages (the more
precise term might be writing systems), to solve various technical
difficulties with having different character sets for different
languages and using them in multilingual contexts. In practice, in
the most recently released Unicode 7.0, it has defined 113,021 code
points, i.e. unique characters. A Unicode code point such as
U+1234 is a character uniquely identified by the
hexadecimal number following U+. Unicode itself does
not specify how characters are represented on computer storage
media as sequences bits, viz. 0s and 1s. UTF-8 is a character
encoding scheme which is a protocol for representing Unicode
points, i.e. the characters as sequences of bits, such as
representing Unicode code point U+00FF, i.e. character
ÿ as 1100001110111111. Conversely, a
piece of text data on computer storage medium, which ultimately is
a sequence of bits cannot be interpreted or decoded, if an
accompanying encoding such as UTF-8 is not given. UTF-8 is an
efficient encoding scheme. Some of its advantages include 1)
backwards compatibility to ASCII so characters in ASCII including
English letters, Arabic numerals, and some regular English
punctuations are represented by the exactly same sequences of bits
in ASCII and UTF-8, thus old or English-language text data encoded
using ASCII can be exactly decoded with UTF-8 as well, which
minimizes compatibility glitches; 2) variable length of bit
sequences for representing individual characters to reduce space
wasted for padding and disambiguation. And the encoding
scheme sketched in the Wikipedia article "UTF-8" is useful to
quickly remind one of the related concepts. I'll see if I can add
more to this in future.
Mathematica, the software that I use all the time in and outside
of my work only support plane-0 Unicode characters (at least in the
front-end, i.e. the notebook interface), that is
U+0000 to U+FFFF, which unfortunately
misses out many Chinese radicals in classical Chinese texts. I used
to developed some prototypes for natural language processing with
Chinese classical texts in Mathematica, but because of this
limitation, it could not get quite nicely done. Databases is
another context where careful treatment to character
set and character encoding issues and collations can become
involving. My most frequently used database is MySQL, in 5.5+,
there is
utf8mb4 which supports storing 4-byte-wide Unicode
characters which is quite broad.
The ranges of Unicode code points representing Chinese, Japanese and Korean (CJK) characters (as I identified) are
- [
U+4E00,9FFF] - [
U+3400,4DFF] - [
U+F900,FAFF] - [
U+20000,2A6DF] - [
U+2F800,2FA1F]
Some useful references:
-
http://www.fileformat.info/info/unicode/, e.g. ü
-
http://www.wolframalpha.com, e.g. ü
-
A reference about sorting http://collation-charts.org
-
Unicode.org has some computer-readable data files: http://www.unicode.org/Public/UNIDATA/
And, lastly, the technically precise way to write the two words
is Unicode and UTF-8, not
unicode, utf8 or UTF8.
In my .emacs, I set "Source Code Pro" as my default
font and solarized-dark as my default theme. But
occasionally, I'd like to switch the theme and font in the current
Emacs frame. After some Internet research, I find the commands to
do this:
- to swith theme to
solarized-light, do
M-x, load-theme,
Enter, solarized-light
In Emacs 24+, one can also interactively set font using mouse by
M-x, mouse-set-font, and
selecting font faimily, typeface, size in the Fonts pop-up
window.
- to swith font, do
M-x, set-frame-font,
Enter, Space (trigger auto-completition to
look for candidates, and use Up, Down to
switch font), Enter
References
Blog (en, zh|中文)
| ← | March 2021 | |||||
|---|---|---|---|---|---|---|
| S | M | T | W | T | F | S |
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 | |||
Feeds
![]() Twitter
Twitter
![]() Google+
Google+
![]() Sina Weibo 新浪微博
Sina Weibo 新浪微博
Photos
![]() portfolio
portfolio
![]() photo stream
photo stream
Links
优雅琴声
| blog | 11 |
| computing | 10 |
| note | 8 |
| programming | 3 |
| tip | 3 |
| Java | 2 |
| bash | 2 |
| china | 2 |
| chinese | 2 |
| data | 2 |
| emacs | 2 |
| git | 2 |
| journal | 2 |
| linguistics | 2 |
| mathematica | 2 |
| mathematics | 2 |
| mercurial | 2 |
| news | 2 |
| revision control | 2 |
| statistics | 2 |
This is a note on how to save Kuvva wallpaper images automatically.
Kuvva is a desktop wallpaper app. It automatically streams beautiful images to one's computer as wallpapers. Every week they introduce a featured artist whose selected work is streamed. I've used the service for a while and like the selection much.
On Mac 10.8+, one can find information of the desktop wallpaper images with the following command
$ plutil -p ~/Library/Preferences/com.apple.desktop.plist
More concise result with only image file paths:
$ plutil -p ~/Library/Preferences/com.apple.desktop.plist | grep "\"ImageFilePath\"" | sed 's/^ *//' | sort
"ImageFilePath" => "/Users/lumeng/Library/Caches/com.kuvva.Kuvva-Wallpapers/Wallpapers/2728c21dc3d845f1b05c209cded453a3"
"ImageFilePath" => "/Users/lumeng/Library/Caches/com.kuvva.Kuvva-Wallpapers/Wallpapers/ba94b2bd2056554428d9792fe6523877"
"ImageFilePath" => "/Users/lumeng/Library/Caches/com.kuvva.Kuvva-Wallpapers/Wallpapers/ba94b2bd2056554428d9792fe6523877"
"ImageFilePath" => "/Users/lumeng/Library/Caches/com.kuvva.Kuvva-Wallpapers/Wallpapers/ba94b2bd2056554428d9792fe6523877"
"ImageFilePath" => "/Users/lumeng/Library/Containers/com.kuvva.Kuvva-Wallpapers/Data/Library/Application Support/Kuvva/1ac5adfe90bd5b73367769111329ddf9de396d3e"
"ImageFilePath" => "/Users/lumeng/Library/Containers/com.kuvva.Kuvva-Wallpapers/Data/Library/Application Support/Kuvva/1ac5adfe90bd5b73367769111329ddf9de396d3e"
"ImageFilePath" => "/Users/lumeng/Library/Containers/com.kuvva.Kuvva-Wallpapers/Data/Library/Application Support/Kuvva/1ac5adfe90bd5b73367769111329ddf9de396d3e"
"ImageFilePath" => "/Users/lumeng/Library/Containers/com.kuvva.Kuvva-Wallpapers/Data/Library/Application Support/Kuvva/2f47f6bcbb93acb1729beeb9177e2a64c3b688dc"
It turns out every image used as wallpaper will be cached in
/Users/lumeng/Library/Containers/com.kuvva.Kuvva-Wallpapers/Data/Library/Application Support/Kuvva/
I then added cron job to save the images in a different directory:
$ crontab -l
## save newest Kuvva wallpaper image
@hourly rsync -qrihp "/Users/lumeng/Library/Containers/com.kuvva.Kuvva-Wallpapers/Data/Library/Application Support/Kuvva/" "/Users/lumeng/Dropbox/Image/Wallpaper/kuvva_wallpaper/new/"
## copy new images out
@daily rsync -qrihp "/Users/lumeng/Dropbox/Image/Wallpaper/kuvva_wallpaper/new/" "/Users/lumeng/Dropbox-x4430/Dropbox/DataSpace-Dropbox/Image/Wallpaper/kuvva_wallpaper/"
## add filename extesion to image files names
@daily add-filename-extesion-to-image-files.sh -d "/Users/lumeng/Dropbox-x4430/Dropbox/DataSpace-Dropbox/Image/Wallpaper/kuvva_wallpaper/"
The original file names don't have extension. One can use
ImageMagick's identify utility to detect the image
file type and add file name extension accordingly. The Bash script
I'm using to do that
add-filename-extension-to-image-files.sh:
#!/usr/bin/env bash
## Summary: identify image file type and add filename extension appropriately when applicable
## Example:
## $ add-filename-extension-to-image-files.sh -d ~/temp
IMAGE_FILE_DIR=
while getopts d:d opt; do
case $opt in
d)
IMAGE_FILE_DIR=$OPTARG
;;
esac
done
if <span class="createlink"> -d $IMAGE FILE DIR </span>; then
FILES=`find $IMAGE_FILE_DIR -maxdepth 1 -type f`
else
FILES=()
fi
IMAGEMAGICK_IDENTIFY_BIN="/opt/local/bin/identify"
for file in $FILES
do
filename=$(basename "$file")
extension="${filename##*.}"
if [ "$extension" == "$filename" ]; then
newextension=`$IMAGEMAGICK_IDENTIFY_BIN $file | cut -d ' ' -f 2 | tr '[:upper:]' '[:lower:]'`
rsync -qrthp $file "$file.$newextension"
rm $file
fi
done
## END
Meng Lu, 2013-7-6
Suppose you want to remove newlines in between the Chinese characters:
南海少年遊俠客,
詩成嘯傲凌滄州,
曾因酒醉鞭名馬,
生怕情深累美人。
-- note that the 1st and 2nd Chinese comma ,
actually have two or more white spaces following them -- and change
it to a single line
南海少年遊俠客,詩成嘯傲凌滄州,曾因酒醉鞭名馬,生怕情深累美人。
One way to do this is using Emacs.
Use query-replace-regexp
Press M-x, and type
query-replace-regexp, or as a shortcut
C-M-%;
Type regexp to match:
\([[:nonascii:\]]\) *
*\([[:nonascii:\]]\)
Note the line break in the regexp need to be typed into the Emacs minibuffer with C-q C-j.
Type regexp to substitute:
\1\2
This means the white space character(s) (if any) and newline character between non-ASCII characters will be removed in the substituted version, so the result is the character on the first line followed by that on the second line.
Use fill-paragraph
-
Set
fill-columnvariable, which controls how wide a line of text can go before line-wrapping to a very large value for the current buffer: C-xf,10000000 -
Highlight the paragraph you'd like to modify: move cursor to the beginning, hold Shift down and move up and down arrow to extend and decrease the selection;
-
Press M-x, and type
fill-paragraph.
This should remove all newline characters in the text. Interestingly, if there are multiple white space characters at the end of lines before the new line character, it will keep one of them:
南海少年遊俠客, 詩成嘯傲凌滄州, 曾因酒醉鞭名馬,生怕情深累美人。
Note there is an additional white space after the 1st and the
2nd ,.
The single white space character is actually still redundant, that can be corrected by
M-x query-replace-regexp
, *
,
After reading "The ASA's statement on p-values: context, process, and purpose", and some other related references, here are some excerpts and notes I took on p-value and null-hypothesis significance testing.
-
American Statistical Association (ASA) has stated the following five principles about p-values and null hypothesis significance testing:
- "P-values can indicate how incompatible the data are with a specified statistical model."
- "P-values do not measure the probability that the studied hypothesis is true, or the probability that the data were produced by random chance alone."
- " … It is a statement about data in relation to a specified hypothetical explanation, and is not a statement about the explanation itself."
- "Scientific conclusions and business or policy decisions should not be based only on whether a p-value passes a specific threshold."
- "… Practices that reduce data analysis or scientific inference to mechanical “bright-line” rules (such as “p < 0.05”) for justifying scientific claims or conclusions can lead to erroneous beliefs and poor decision-making. …"
- "Proper inference requires full reporting and transparency."
- "A p-value, or statistical significance, does not measure the size of an effect or the importance of a result."
- "… Smaller p-values do not necessarily imply the presence of larger or more important effects, and larger p-values do not imply a lack of importance or even lack of effect. Any effect, no matter how tiny, can produce a small p-value if the sample size or measurement precision is high enough, and large effects may produce unimpressive p-values if the sample size is small or measurements are imprecise. …"
-
Null hypothesis is usually a hypothesis that assumes that observed data and its distribution is a result of random chances rather than that of effects caused by some intrinsic mechanisms. It is usually what is to disapprove or to reject in order to establish evidence to or belief in that there is some real effect due to underlying intrinsic mechanism. In turn, the details of the statistical model used in this evaluation can be used to make quantitative estimations on properties of the underlying mechanism.
-
The p-value is the probability that one has falsely rejected the null hypothesis.
- The smaller is, the smaller the chance is that one has falsely rejected the null hypothesis.
- Being able to reject or not being able to reject the null hypothesis may tells one if the observed data suggests that there is an effect, however, it does not tell one how much an effect there is and if the effect is true. See effect size.
- "a p-value near 0.05 taken by itself offers only weak evidence against the null hypothesis".
- UK statistician and geneticist Sir Ronald Fisher introduced the p-value in the 1920s. "The p-value was never meant to be used the way it's used today."
-
As ASA p-value principle No. 3 states, the decision to reject the null hypothesis should not be based solely on if p-value passes a "bright-line" threshold. Rather, in order to reject the null hypothesis, one must make a subjective judgment involving the degree of risk acceptable for being wrong. The degree of risk of being wrong may be specified in terms of confidence levels which characterizes the sampling variability.
-
Alternative ways used for referring to data cherry-picking include data dredging, significance chasing, significance questing, selective inference, p-hacking, snooping, fishing, and double-dipping.
-
"The difference between statistically significant and statistically insignificant is not, itself, statistically significant."
-
"According to one widely used calculation [1], a p-value of 0.01 corresponds to a false-alarm probability of at least 11%, depending on the underlying probability that there is a true effect; a p-value of 0.05 raises that chance to at least 29%." See the following figure:
p-value and probable cause.png
Some related concepts
-
The standard score, or z-score is the deviation from the mean in units of standard deviation. A small p-value corresponds to a large positive z-score.
-
- Magnitude - How big is the effect? Large effects are more compelling than small ones.
- Articulation - How specific is it? Precise statements are more compelling than imprecise ones.
- Generality - How generally does it apply?
- Interestingness - interesting effects are those that "have the potential, through empirical analysis, to change what people believe about an important issue".
- Credibility - Credible claims are more compelling than incredible ones. The researcher must show that the claims made are credible.
References
-
"The problem with p-values: how significant are they, really?", phys.org Science News Wire, 2013, http://phys.org/wire-news/145707973/the-problem-with-p-values-how-significant-are-they-really.html
-
Regina Nuzzo, "Scientific method: statistical errors," 2014, http://folk.ntnu.no/slyderse/Nuzzo%20and%20Editorial%20-%20p-values.pdf
-
Tom Siegfried, "Odds Are, It's Wrong - Science fails to face the shortcomings of statistics," 2010, https://www.sciencenews.org/article/odds-are-its-wrong
-
Gelman, A., and Loken, E., "The Statistical Crisis in Science," American Scientist, 102., 2014, http://www.americanscientist.org/issues/feature/2014/6/thestatistical-crisis-in-science
-
"The vast majority of statistical analysis is not performed by statisticians," simplystatistics.org, 2013, http://simplystatistics.org/2013/06/14/the-vast-majority-of-statistical-analysis-is-not-performed-by-statisticians/
-
"On the scalability of statistical procedures: why the p-value bashers just don't get it," simplystatistics.org, 2014, http://simplystatistics.org/2014/02/14/on-the-scalability-of-statistical-procedures-why-the-p-value-bashers-just-dont-get-it/
-
Andrew Gelmana and Hal Sterna, The Difference Between “Significant” and “Not Significant” is not Itself Statistically Significant, The American Statistician, Volume 60, Issue 4, 2006, http://www.tandfonline.com/doi/abs/10.1198/000313006X152649
- Goodman, "Of P-Values and Bayes: A Modest Proposal," S. N. Epidemiology 12, 295–297 (2001), http://journals.lww.com/epidem/fulltext/2001/05000/of_p_values_and_bayes__a_modest_proposal.6.aspx↩
Principle of the single big jump
Learned about an interesting probability principle about random walk called "principle of the single big jump"
A high overall displacement with respect to the orgin resulting from doing random walk might be essentially contributed by one single very large step, i.e. a leap.
Technically, assume the step sizes are independent random variables with heavy-tailed (technically, subexponential) distributions, then the maximum and the sum have the same asymptotic distribution. That is, as x goes to infinity,
References:
-
http://arxiv.org/pdf/math/0509605v1.pdf
-
http://www.johndcook.com/blog/2011/08/09/single-big-jump-principle/
Here is some notes about running forms:
The Pose Method running
-
as foot lands on ground, shoulder, hip and ankle are aligned to a straight line and sloped forward
-
lands on forefoot
Chi running
Aims at mechanical efficiency and injury-free.
-
postural alignment: align shoulder, hip and anckle to a straight line (posture line)
-
midfoot (full foot) landing under posture line
-
forward lean from relaxed ankles
-
heel lift via knee bend
-
arm swing to the rear
Kenyan elite runner Moses Mosop's running form in slow motion. (It seems sometimes his landing foot is in front of his hip horizontal position, but not sure if it's also in front of the overall center of gravity of the body.
Bare foot running
Just one key point: run barefoot and let it land naturally on forefoot instead of on heel. Wearing running shoes makes it comfort to land on heels and easy to injure yourself.

Gradle (http://www.gradle.org/) is a modern software building automation tool. I've recently picked it up. Here is a note on setting up a minimal and not-entirely-trivial Java project using Gradle and building (including running tests) with it: 〈 Installing and configuring Gradle 〉.
A few numbers to illustrate how bad 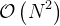 time complexity
is, just so the well known fact is more concrete. It does not take
much to make it useless for practical purposes in the Big Data
era.
time complexity
is, just so the well known fact is more concrete. It does not take
much to make it useless for practical purposes in the Big Data
era.
The plot 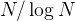 vs.
vs. 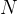 , should illustrate how large the
difference between the two growth rates and
, should illustrate how large the
difference between the two growth rates and 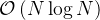 really is:
at some time scale, a computation with input size
really is:
at some time scale, a computation with input size 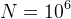 can be computed within a day by
but will
take about two human lifetimes (about 50000 days) to do:
can be computed within a day by
but will
take about two human lifetimes (about 50000 days) to do:
 and O(N^2) time complexities<figcaption>")
With the advent of Java 8 and
java.util.stream and
lambda expressions in it, one can do data munging in Java 8 as
the following:
Java 8:
public static void main(String[] args) {
HashMap<Integer, Character> nucleobases = new HashMap<> ();
nucleobases.put(1, 'A');
nucleobases.put(2, 'G');
nucleobases.put(3, 'T');
nucleobases.put(4, 'C');
range(0, 100)
// generate a stream containing random strings of length 10
.mapToObj(i -> randomNucleicAcidSequence(new Random(), nucleobases, 10))
// sort the elements in the stream to natural ordering
.sorted()
// group strings into sub-lists and wrap them into a stream
.collect(groupingBy(name -> name.charAt(0)))
// print each sub-list's common initial letter and the constituent strings
.forEach((letter, names) -> System.out.println(letter
+ "\n\t"
+ names.stream().collect(joining("\n\t"))));
}
public static String randomNucleicAcidSequence(Random r, Map<Integer, Character> map, int length) {
return r.ints(1, 4).limit(length).mapToObj(
x -> Character.toString(map.get(x))).collect(Collectors.joining());
}
This is remarkbly similar to a program written in Mathematica using the munging style I use all the time:
(* There is not a built-in RandomString[…] *)
nucleobases = {"A", "G", "T", "C"};
randomNucleicAcidSequence[length_Integer] := StringJoin[nucleobases[[#]] & /@ RandomInteger[{1, 4}, length]]
Composition[
Print[StringJoin[{#[[1]],":\n",StringJoin[Riffle[#[[2]],"\n"]]}]]& /@ # &,
(First[Characters[Part[#, 1]]]-> #) & /@ # &,
GatherBy[#, First[Characters[#]]&]&,
Sort,
Map[Function[{i}, randomNucleicAcidSequence[10]], #] &
][Range[0, 100]]
The output of both program print the mucleic acid sequences grouped by initial neuclobase:
A:
AAAATACCTC
AAATAATCAT
AACAGATACG
ACAACTACGG
ACCATCAAAT
...
C:
CAACGGGGTT
CAAGAAGAGC
CACACCCACA
CACACTCTAC
CAGGACCGGA
...
G:
GAACGTTTCA
GAACTAAGCG
GACCAGTTCT
GAGAACACGT
GAGCCGCCAC
...
T:
TAAAATTGCC
TAAGGTGAGG
TAGCCGGTTA
TAGGCGGTGA
TAGTTCGAGC
...
Data streams and algorithms for processing them is a recently hot research area in computer science. It seems to me it will be natural for Java standard library to include more and more stream algorithms in future.
Related:
After reading many references and trying various settings, I finally got Oracle JDK 7 and JDK 8 installed on my MacBook Pro running OS X 10.9.2, while leaving macOS's own system Java which is Java 6 unchanged. I've written a note 〈 Installing and configuring Java on Mac 〉.
Using or matching backslash character ('\') correctly with
grep or similar tools such as ack takes
some investigation. Here is a note on what I found.
GNU grep
I created a text file temp.txt with
\
\\
\\\
\:0251
What I get from trying to match each line with grep
(GNU bash 3.2.48) from Bash command line:
-
Use
"\\\\"to match\$ grep -x --color=always "\\" temp.txt \
-
So to match
\\,\\\\\\\\is needed:$ grep -x --color=always "\\\\" temp.txt \
-
To Match
\:0251which is the MathematicaInputFormstring of a Chinese character:$ grep -x --color=always "\\:0251" temp.txt :0251
A tree graph is uniquely identified by the set of its edges
{1->2, 1->3, 2->4, 2->5, 2->6, 3->7, 3->8}
This syntax is used in Wolfram Language's graph specification. The actual picture of the graph can be displayed in Mathematica with:
Graph[{1 -> 2, 1 -> 3, 2 -> 4, 2 -> 5, 2 -> 6, 3 -> 7, 3 -> 8}]
The question is: is there a better way to represent the graph in a compact, readable, and text-only form?
Why?
A few use cases which might give some motivation:
-
In tweets, sometimes, one might want to include graphs accurately represented by a short sequence of regular characters, which ideally should also be easy to parse as-is (instead of only after being processed by software such as Mathematica's
Graph[...]function.) -
When labeling/classifying objects, besides using tags which are a flat list of IDs of form
{tag1, tag2, ...}and equivalent to a graph with vertexes but no edges, one can use a tree graph represented in a succinct form to carry more information about the hierarchical classification of the object.
One way: list of tags
One obvious way is to write the list of edges such as
{1->2, 1->3,2->4, 2->5, 2->6, 3->7,
3->8}, which uniquely identifies the graph. It's not very
compact -- vertexes with multiple children is repeated -- and
neither very readable -- one need to do much mental processing and
memorizing in order to understand and imagine the structure of the
graph.
Another way: "graphlet"
Another way I designed is to write it into the following form, which I dubbed "graphlet representation" of (tree) graphs:
1`{2`{4, 5, 6}, 3`{7, 8}}
So, in graphlet representation:
-
The edges in a graph are represented by an edge character (backtick for instance);
-
Child vertexes are grouped by a pair of grouping characters (
{and}for instance).
Note that the graphlet representation is shorter than the flat list-of-edges representation.
Classification graphlet is more informative than list of tags
An object's classification is often represented as a list of tags
{tag1, tag2, ..., tag8}
However, if the classification is hierarchical, a graphlet representation can easily records more information about the classification structure:
tag1`{tag2`{tag4, tag5, tag6}, tag3`{tag7, tag8}}
Application examples
To represent the classification of a problem, a sequence of key words is often used, e.g.
astrophysics, cosmology, general-relativity, star, galaxy
One can actually additionally include its hierarchical classification structure by using a graphlet:
science`{physics`{astrophysics, cosmology, general-relativity}, astronomy`{star, galaxy}}
Advantages
Preserving the full graph structure, many graph characteristics can be exploited, and graph-theoretic methods can be used for analyzing metadata in this form. For example, graphlets can be systematically shorten/simplified by pruning leaves.
In Mathematica and Wolfram Language, with the feature called Texture it's easy to draw 3D solids such as polyhedra with image textures on the surface such as the faces of polyhedra. When playing with this, I drew a rhombic hexecontahedron (properties), the logo of Wolfram|Alpha with national flags on its faces:

☝ Rhombic hexecontahedron wrapped with the 60 most populous countries' national flags, one different flag drawn on each of the 60 rhombic faces. (It's somewhat odd that the most populous countries happen to have a lot of red and green colors in their national flags.)
The code is in my Git repository.
Remarks:
- It was a bit tricky to understand what the option
VertexTextureCoordinates is and does, and how to set it up for
what I'm trying to draw. It turns out for putting the national
flags on the faces of a rhombic hexecontahedron, since both are
(usually) isomorphic to a square,
VertexTextureCoordinates -> {{0, 0}, {1, 0}, {1, 1}, {0, 1}}is would work as it aligns the four vertices of a rectangular flag to the four vertices of a rhombic face.
Something left to be improved:
-
Avoid flags that's not isomorphic to the face of the given polyhedron;
-
Compute the suitable values of
VertexTextureCoordinatesto reduce or even avoid distortion of the flags; -
Find a reasonable way to align national flags of shapes not isomorphic to the shape of a face of a given polyhedron, such that the main feature of the national flag wrapped on a polyhedron face is well recognizable.
Wrote a note
about backing up MediaWiki including its database (MySQL or
SQLite), content pages exported as an XML file, all images, and the
entire directory where MediaWiki installed, which includes
LocalSettings.php and extensions that usually contain
customization.
Use rlwrap to enable arrow keys, command history,
history completion and search
$more mma.sh
#!/usr/bin/env bash
rlwrap --file /opt/local/share/rlwrap/MathKernel /Applications/Mathematica.app/Contents/MacOS/MathKernel
$ ./mma.sh
Mathematica 8.0 for macOS x86 (64-bit)
Copyright 1988-2011 Wolfram Research, Inc.
In[1]:= 1+Sin[2]//N
Out[1]= 1.9093
In[2]:=
At an input In[XXX], one can
-
press up and down arrow keys to insert previously entered commands
-
press left and right arrow keys to move cursor
Use XXX to colorise terminal
Getting myself ready to take two courses this fall, online. This will actually be my first experience of "distance education", or the closest thing to it.
The two courses are
-
Sebastian Thrun, Peter Norvig, Introduction to Artificial Intelligence (
http://www.ai-class.com) -
Jonathan Worth, #PHONAR – Photography and Narrative (
http://phonar.covmedia.co.uk)
I'm taking them because i am interested in the subjects and hopefully can put the theory and knowledge I learned into real use.
Was trying to come up with some style guide for commit messages in revision control systems (Subversion, Git, Mercurial, etc.) as very commonly it is a place where people tend to use poor or poorly-managed writing styles when they are in a hurry, or not. The contrast between the sophistication of engineering of automatic revision control systems and the lousiness of majority of commit messages I've seen is ironic, at least to me. Imagine a situation where one wants to data mine the commit message history in a revision control repository and do text analytics with it to find out some interesting thing about the project, it can be very useful for the commit messages to have a uniform format and hence more machine processable.
Some general rule for revisions and commits
- try to make a commit self-contained, i.e. logically-closely-related revisions should be committed together in one commit rather than in multiple separate commits
- try to make logically-unrelated revisions in their own separate commits rather than make a big revision including many changes that are logically independent to each other
Some general rules for having uniform format of the commit messages
-
Use a short summary sentence at the top to summarize the main purpose/content of the revision. As both Git and Mercurial use the first sentence ending with period (
.) for various purposes. If there are itemized details in the following, use ellipsis (...) instead. -
Leave a blank line below the summary sentence.
-
Keep the lines shorter than 72 characters as that produces better line wrapping behavior for
hg logandgit log. -
If necessary, use bullet items below the blank line to describe details. Use different bullet for different types of revisions
-
+added new content -
-removed existing content -
%modified existing content and/or behavior -
!fixed bugs and errors -
~tweaked content by making small and/or insubstantial changes -
*misc and/or other unclassified changes -
>to-do for future
-
-
Try to use expressions with simple past tense or noun phrases.
Example commit message to a revision control repository:
Changed the logic dealing with magic input.
+ added an awesome new functionality
- removed obsolete content
% modified some existing code
! fixed a bad bug
~ tweaked some content
* some misc unclassified changes
> make the logic more robust
"I read a study that measured the efficiency of locomotion for various species on the planet. The condor used the least energy to move a kilometer. Humans came in with a rather unimpressive showing about a third of the way down the list....That didn't look so good, but then someone at Scientific American had the insight to test the efficiency of lomotion for a man on a bicycle and a man on a bicycle blew the condor away.
That's what a computer is to me: the computer is the most remarkable tool that we've ever come up with. It's the equivalent of a bicycle for our minds."
The prestigious scientific magazine Nature published a news report titled 'Oympic feats raise suspicion' by Ewen Callaway (@ewencallaway), which talked about 16-year-old Chinese Olympic gold medalist swimmer Ye Shiwen, and says
... how an athlete's performance history and the limits of human physiology could be used to catch dopers ...
Was Ye’s performance anomalous?
Yes. Her time in the 400 IM was more than 7 seconds faster than her time in the same event at a major meet in July 2011. But what really raised eyebrows was her showing in the last 50 metres, which she swam faster than US swimmer Ryan Lochte did when he won gold in the men’s 400 IM on Saturday, with the second-fastest time ever for that event. ...Doesn't a clean drug test during competition rule out the possibility of doping?
No, says Ross Tucker, ...
Other than this fact-lacking and logically flawed weak reasoning, there is not much data or scientific analysis in this report. It seems a rather substandard article for Nature, especially on a potentially controversial topic. One of the reader comments was particularly well-ground criticism on it:
Lai Jiang said:
It is a shame to see Nature, which nearly all scientists, including myself, regard as the one of the most prestigious and influential physical science magazines to publish a thinly-veiled biased article like this. Granted, this is not a peer-reviewed scientific article and did not go through the scrutiny of picking referees. But to serve as a channel for the general populous to be in touch with and appreciate sciences, the authors and editors should at least present the readers with facts within proper context , which they failed to do blatantly.
First, to compare a player's performance increase, the author used Ye's 400m IM time and her performance at the World championship 2011, which are 4:28. 43 and 4:35.15 respectively, and reached the conclusion that she has got an "anomalous" increase by ~7 sec (6.72 sec). In fact she's previous personal best was 4:33.79 at Asian Games 2010 [1]. This leads to a 5.38 sec increase. In a sport event that 0.1 sec can be the difference between the gold and silver medal, I see no reason that 5.38 sec can be treated as 7 sec.
Second, as previously pointed out, Ye is only 16 years old and her body is still developing. Bettering oneself by 5 sec over two years may seem impossible for an adult swimmer, but certainly happens among youngsters. Ian Thorpe's interview revealed that his 400m freestyle time increased 5 sec between the age of 15 and 16 [2]. For regular people including the author it may be hard to imagine what an elite swimmer can achieve as he or she matures, combined with scientific and persistent training. But jumping to a conclusion that it is "anomalous" based on "Oh that's so tough I can not imagine it is real" is hardly sound.
Third, to compare Ryan Lochte's last 50m to Ye's is a textbook example of what we call to cherry pick your data. Yes, Lochte is slower than Ye in the last 50m, but (as pointed out by Zhenxi) Lochte has a huge lead in the first 300m so that he chose to not push himself too hard to conserve energy for latter events (whether this conforms to the Olympic spirit and the "use one' s best efforts to win a match" requirement that the BWF has recently invoked to disqualify four badminton pairs is another topic worth discussing, probably not in Nature, though). On the contrary, Ye is trailing behind after the first 300m and relies on freestyle, which she has an edge, to win the game. Failing to mention this strategic difference, as well as the fact that Lochte is 23.25 sec faster (4:05.18) over all than Ye creates the illusion that a woman swam faster than the best man in the same sport, which sounds impossible. Put aside the gender argument, I believe this is still a leading question that implies the reader that something fishy is going on.
Fourth, another example of cherry picking. In the same event there are four male swimmers that swam faster than both Lochter (29.10 sec) [3] and Ye (28.93 sec) [4]: Hagino (28.52 sec), Phelps (28.44 sec), Horihata (27.87 sec) and Fraser-Holmes (28.35 sec). As it turns out if we are just talking about the last 50m in a 400m IM, Lochter would not have been the example to use if I were the author. What kind of scientific rigorousness that author is trying to demonstrate here? Is it logical that if Lochter is the champion, we should assume he leads in every split? That would be a terrible way to teach the public how science works.
Fifth, which is the one I oppose the most. The author quotes Tucks and implies that a drug test can not rule out the possibility of doping. Is this kind of agnosticism what Nature really wants to educate its readers? By that standard I estimate that at least half of the peer-reviewed scientific papers in Nature should be retracted. How can one convince the editors and reviewers that their proposed theory works for every possible case? One cannot. One chooses to apply the theory to typical examples and demonstrate that in (hopefully) all scenarios considered the theory works to a degree, and that should warrant a publication, until a counterexample is found. I could imagine that the author has a skeptical mind which is critical to scientific thinking, but that would be put into better use if he can write a real peer-reviewed paper that discusses the odds of Ye doping on a highly advanced non-detectable drug that the Chinese has come up within the last 4 years (they obviously did not have it in Beijing, otherwise why not to use it and woo the audience at home?), based on data and rational derivation. This paper, however, can be interpreted as saying that all athletes are doping, and the authorities are just not good enough to catch them. That may be true, logically, but definitely will not make the case if there is ever a hearing by FINA to determine if Ye has doped. To ask the question that if it is possible to false negative in a drug test looks like a rigged question to me. Of course it is, other than the drug that the test is not designed to detect, anyone who has taken Quantum 101 will tell you that everything is probabilistic in nature, and there is a probability for the drug in an athlete's system to tunnel out right at the moment of the test. A slight change as it may be, should we disregard all test results because of it? Let's be practical and reasonable. And accept WADA is competent at its job. Her urine sample is stored for 8 years following the contest for future testing as technology advances. Innocent until proven guilty, shouldn't it be?
Sixth, and the last point I would like to make, is that the out-of- competition drug test is already in effect, which the author failed to mention. Per WADA president's press release [5], drug testing for olympians began at least 6 months prior to the opening of the London Olympic. Furthermore there are 107 athletes who are banned from this Olympic for doping. That maybe the reason that everyone will pass at the Olympic games. Hardly anyone fails in competition testing? Because those who did dope are already sanctioned? The author is free to suggest that a player could have doped beforehand and fool the test at the game, but this possibility certainly is ruled out for Ye.
Over all, even though the author did not falsify any data, he did ( intentionally or not) cherry pick data that is far too suggestive to be fair and unbiased, in my view. If you want to cover a story of a suspected doping from a scientific point of view, be impartial and provide all the facts for the reader to judge. You are entitled to your interpretation of the facts, and the expression thereof in your piece, explicitly or otherwise , but only showing evidences which favor your argument is hardly good science or journalism. Such an article in a journal like Nature is not an appropriate example of how scientific research or report should be done.
1 http://www.fina.org/H2O/index.php?option=com_wrapper&view=wrapper&Itemid=1241
2 http://www.youtube.com/watch?v=8ETPUKlOwV4
3 http://www.london2012.com/swimming/event/men-400m-individual-medley/phase=swm054100/index.html
4 http://www.london2012.com/swimming/event/women-400m-individual-medley/phase=sww054100/index.html
5 http://playtrue.wada-ama.org/news/wada-presidents-addresses-london-2012-press-conference/?utm_source=rss&utm_medium=rss&utm_campaign=wada-presidents-addresses-london-2012-press-conference
How well said!
推荐 NHK 的纪录片《圆的战争》。“圆的战争”指的是以操控通货为主的经济战,金融战。日本侵华战争时期通过傀儡国银行(朝鲜银行,中国联合准备银行等)和日本的横滨正金银行勾结,在中国发行实质上无准备金的货币(如“银联券”)扰乱中国经济。日本用这样的货币直接供给在华日军军费,而非直接用日元,而后傀儡银行的日元准备金如数归还日本国库,借此能达到循环不断、无成本、无限地供给军费给侵华日军,“以战养战“的目的。有了这样来的军费支持,侵华日军才能维持长期侵略战争。片中称此手段为“往来借款”:

☝ 示意图:日本以“往来借款”手段支持侵华日军军费
外部链接
- NHK纪录片精选, 圆的战争, http://kamonka.blogspot.com/2011/08/blog-post_19.html
Find the top committers to a file
Mercurial:
$ hg log ./.hgignore | grep user: | sort | uniq -c | sort -r | head -3
5 user: Michael <michael@foomail.com>
3 user: Mary <mary@barmail.com>
Git:
$ git log ./.gitignore | grep ^Author: | sort | uniq -c | sort -r | head -3
6 Author: Michael <michael@foomail.com>
2 Author: Mary <mary@foomail.com>
CVS:
$ cvs log ./foo/bar.cpp | grep author | awk '{print $5}' | sort | uniq -c | sort -r | head -3
92 Michael;
72 Mary;
I recently discovered a tool for checking Java code formatting and other coding style related issues -- CheckStyle. It features a list of style checks such as
...
* Restricts nested boolean operators (&&, ||, &, | and ^) to a specified depth (default = 3).
* Checks for empty blocks.
* Checks for long source files.
...
There's also an Eclipse plugin for it: https://checkstyle.org/eclipse-cs/#!/. The Eclispe update URL is http://eclipse-cs.sf.net/update/. As of at least Eclipse 4.8.0 (Aug., 2018), this update URL no longer works.
There is a caveat at the time I install it:
the plugin's homepage http://eclipse-cs.sourceforge.net/ gives http://sevntu-checkstyle.github.com/sevntu.checkstyle/update-site/ as the installation URL, but it does not work. However on http://eclipse-cs.sourceforge.net/downloads.html a different installation URL http://eclipse-cs.sf.net/update/ is given, which turns out to work correctly. It seems someone has not updated the Web pages consistently. And it has certainly confused some: http://stackoverflow.com/questions/11865025/error-while-installing-check-style-plugin-for-eclipse.
Some raw thoughts about human society's high and accelerating information metabolism.
With mobile phones (~1950-), databases (~1960-), personal computers and computer softwares (~1970-), emails (~1970-), the Web (~1990-), social networks such as blogs, Facebook, Twitter, ... (~2000-), and the latest buzz concepts of computing cloud and big data, human society has undergone an exponential growth in its appetite for data and information, as well as its industrial power of producing, transforming, and distributing data and information. It's mind boggling to think about how the way human deals with data, this artificial raw material, is constantly shaping our current moment of history. If one thinks of human society as a complex physical system; the history is the time evolution of the system. Much of the important events happened in the history that history books happened to have a record for, and -- as a result -- get remembered by the recent generations, had been direct consequences of physical constraints on the system. Limitations tend to introduces complex mechanics and then makes features of the system; unboundedness tend to make a system flat and simple. A good portion of those constraints can be attributed to the physical limits on the volume and speed that human society could produce, transform, understand, and distribute information. Data, information, and knowledge are in order of increasing extent of extraction, abstraction, and purification, in terms of human perception and thinking. But in evolution of society, it is almost exactly the opposite order. Three hundred years ago, there might not be any good way -- and hence any interest -- in doing anything with data, as human were simply not armed with efficient tools to collect data. Good first-hand information about the real world were scarce and normally didn't spread far. Emperor of China then didn't have a good idea of the existence of Europe. And much imagination can be given to what modern history could be different if it was not the case. As electricity and electromagnetic waves were utilized for transforming and distributing information, telegraphs and telephones were inevitably invented, events happening at one place could be learned by people at a different place thousands of miles away shortly after. This means the information metabolism of human society has started accelerating. It's just like human with high metabolic rate have higher heart rate. And like appetite for food, when one eats fast, he is more likely to have need for more food. Since then, human society has observed an accelerating appetite and metabolism of data and information. In the present decade, it is no longer uncommon for an average person to find himself knowing about some trivia about some notable person on the other side of the planet. Information, good or bad, useful or not, is now like air, filling any empty space it can find, seemingly by its own force and law of nature. If the society is a biological creature, its appetite and metabolism for information has certainly grown larger and faster and is acceleratingly growing. Given the analogue to biological metabolism, my next question is: is high information metabolic rate good for us? Are humans designed to live like that? How do you live a healthy life style in terms of information metabolism measures?
Hello world!
参考 Wikipedia 上的 "English spelling alphabet" 根据自己习惯编了这个表。最近常跟 customer service 打电话,经常听(说?)不清的是 C,D,E,H,M,N,X。中国中学英语教科书里其实应该教一下这个 。
English Spelling Alphabet v1.0
- A: Apple
- B: Boy
- C: Cat
- D: Dog
- E: Elephant
- F: Flower
- G: Girl
- H: Hotel
- I: India
- J: John
- K: Kiss
- L: Lincoln
- M: Mary
- N: November
- O: Orange
- P: Peter
- Q: Queen
- R: Roger
- S: Sugar
- T: Tom
- U: Umbrella
- V: Victory
- W: William
- X: X-ray
- Y: Yellow
- Z: Zebra
